A job scheduling tool for massively parallel processing designed for heterogeneous data warehouse environments. It is built over a Java application server. Process management in GTL Scheduler is based on the definition of dependencies between tasks and resources (for example, locks, files, spreadsheets, etc.). Tasks are launched as soon as their dependencies on other tasks and objects are fulfilled. Specific arrangement and parallelisation size are left to the tool responsible for the process control. User interface as a web application use different user roles and allows daily data processing monitoring and administration.
Job scheduler – dependency graph
One of the primary goal of globtech scheduler is to provide maximum flexibility to organization of jobs. We have chosen simple but powerful kind of organization – dependency graph. A dependency graph is composed of objects like job, lock or connector and dependencies among them. Two jobs can be synchronized using predecessor-successor dependency. If this kind of dependency is not sufficient lock can be used. Lock is typically used as an abstraction for table, file etc. to assure restricted access of jobs to a resource. Access can be fully exclusive or shared with limited number of actual users. Connector is another type of object, which is used by jobs to access target environments like databases or file systems. As for locks, connectors can be restricted for concurrent access as well.
Dependency graph has many advantages over other organizations like tree organization or workflow. Above all they are:
- Maximally clear arrangement of jobs – any two jobs are equal and does not define hierarchy. It is then easy to look up for the real direct or indirect dependencies. On contrary, trees or workflows add unnecessary dependencies because of their structure. Jobs are often grouped on similarity or modularity rules which induces more dependencies than is needed for correct run.
- Easy administration – changing job dependencies means simply changing the dependencies. No tree reorganization, no workflow/subworkflow redesign is necessary not mentioning that reorganization can be very tricky and error prone.
- Maximum autonomy of jobs – all you need to define is the dependencies necessary for correct execution. It helps scheduler to effectively order jobs for execution. Operator can easily and effectively restart or skip sets of selected jobs.
Job scheduling
Job processing based on dependency graph allows maximum parallelism, which can be used for various methods of scheduling. The simplest one that is used in scheduler is scheduling by priorities. But more important method for processing of big graphs of jobs is scheduling based on statistics of previous job executions. Goal of this scheduling method is to prefer jobs from critical paths and thus complete the whole execution in the least possible time, which is crucial requirement for etl processing.
Another criterion of job scheduling, which is orthogonal to the previous ones, is load-balancing. Load-balancing constrains the job selection by keeping maximum acceptable level of target environment load not exceeded. For better estimate of expected load during job execution collecting of statistics of previous executions are helpful. Load-balancing is important in effective job scheduler because even small exceeding of server resources (typically it is memory) can significantly prolong the execution time of the job processing. Shortage of free memory causes swapping of memory pages. Similarly overloaded data cache in database server causes lots of page misses. Both examples increase number of i/o read and write disk operations, which are very time expensive.
Software architecture
Scheduler has the following subparts: repository database, runtime database, runtime server and user console.
Schema
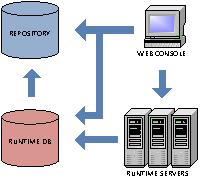
- Repository database contains metadata like graph definition. Definitions can be parameterized, which is useful for example for definition of extract file set i.e. files containing the same kind of data and differ only in their names containing date of export. Repository can be accessed using db api (views and stored procedures). DB api can be used for advanced metadata generation using other types of metadata.
- Runtime database contains actual state of objects and other operational and history data like event log, statistics, etc.
- Runtime server is a service (demon) process that is responsible for job selection (load-balancing), execution, monitoring and collection of statistic. One service is able to execute multiple jobs in parallel (maximum number is dynamically changeable). It is also possible to spawn multiple services in cooperating mode or backup mode.
- Web console is intranet user interface for metadata administration, controlling a monitoring of jobs, resources and other objects. console is described in detail below.
List of functionality
Repository and runtime database
- Scheduler is strongly oriented on database applications, that is why we support db api. Database always contains actual data.
- Database variables are similar to system environment variables and can be used for metadata parameterization e.g. jobs can be created based on business data or environment or active statistics, etc.
Connector
- Uniform access to target environment – abstraction from concrete connection, e.g. connector with the same name can be mapped to different database in test environment and in production. Metadata remains the same. It is possible to map more than one connector to one target environment.
- Use of credentials in uniform way (see server).
- Ability to manage load balancing using max number of parallel access.
- Ability to restrict access to connector for exclusive access.
- Temporary blocking connector by operator or programmatically using db api.
Lock
- Used for additional synchronization among jobs. Lock can be used as an abstraction of file, table, database, processor or any kind of resource whose parallel access needs to be synchronized.
- Lock can be used as a trigger or a latch (lock that is locked by default) and can be released on demand by operator or programmatically using db api. This kind of lock can be used to launch processing of subgraph of jobs dependent on external system. The subgraph processing can then be triggered programmatically using db api or by an operator.
Job
- System jobs – ability to launch any executable file in the operating system where the runtime server runs.
- Enabled/disabled – ability to block/unblock job execution by operator or programmatically using db api.
- Abort – ability to abort job.
- Skip – ability to skip job, which means scheduling the job for skipping. The real skipping is done when the job would be ready to run and would have resolved all dependencies thus all successor jobs are waiting since skipping job predecessors are resolved and the skipping job is skipped and resolved.
- Timeout – ability to set timeout for job execution. the timeout event can be handled by an action (e.g. abort) or by sending an alert.
- Deadline – ability to set an expected time of completion on a job. This attribute is used for preferential job scheduling based on critical paths in graph.
- Priority – ability to set a priority on a job. Typically priority is less significant for job scheduling than effective priority (computed from critical paths) and so is not important except the immediate priority that causes job to be executed immediately (still dependencies have to be satisfied).
- Statistics – ability for statistics collecting. Multiple statistics can be defined depending on time period like daily statistics, month ultimo statistics etc.
- Restart count, restart delay – ability to set automatic restart of job in case of a failure with max count of repeat and a delay between two executions.
- Event handling – ability to handle job execution events with an action. events are: on start, on finish, on end, on success, on error, on abort, on expire, on skip.
- Recovery plan – complex way of treatment of job finish or timeout.
- Job history – every job has recorded history of its execution. History contains basic job info and all output attributes like number of inserted/updated/deleted rows. Set of output attributes can be extended and is configurable in job type metadata.
Runtime server
- Can run as native service or as part of application server.
- Fail-over – timestamp of last activity, handled lost connection to database, in case of lost connection to database critical operations are repeated with some period until they succeeds, backup runtime servers.
- Ability to set server to idle state that causes suspension of new job processing.
- Ability to set maximum number of currently running jobs on the server or time period for looking up for new jobs.
- System logs – configurable format and file name of log files, configurable maximum size and splitting to multiple log files. Level of logging is configurable for different parts of server or modules independently. Log records are easily identifiable with server, worker, and job. Ability to log into windows system log or other 3rd party logging software supporting log4j library.
- Event log – important events that occurred in scheduler are logged into runtime. Ability to log user defined events from service job, event handler or from database using db api.
- Alerts – events can be matched with rules for alerts and in case of match an alert occurs and an email is sent.
- Credentials – saved in runtime database (managed by operator) or in server configuration (managed by system administrator). Integration with java keystores including system keystore in windows.
- Mailer – simple service for email delivery that is used for email notification. Mailer service can be used in service job or event handler.
- Statistics collecting – automatic collecting of statistics of job executions. Collecting can be disabled that is useful in cases when statistics are generated by external procedures.
- Environment variables – server propagates environment variables of operating system to jobs, moreover, server propagates job properties of java runtime environment and variables of runtime database and runtime server (saved in runtime database and managed by operator).
- Extendibility – server can be easily integrated with any java library and functions can be exported to scheduler expression language. Libraries that require lifecycle management can be integrated as internal services.
Target environments
- System jobs – ability to launch any executable file in the operating system and record standard and error outputs and archive them.
- RDBMS database – access through jdbc api to any jdbc enabled database. Ability to execute any kind of command supported by the jdbc driver. Support of input and output parameters (output parameters can be archived in job history). Database command can be composed dynamically using expression language.
- Informatica integration services – support of native api that allows to launch and control workflows in integration server. After workflow completion logs and statistics can be downloaded, saved and accessed from the console.
- File transfer – scheduler supports file transfer from/to local file system and servers supporting http(s), webdav, ftp(s), sftp, scp, samba protocols. For authentication user/password or client/server certificate can be used (concrete support of authentication method depends on whether connector library supports it or not).
- Servis job – allows to execute a command in the runtime server. Explicitly exported functions can be executed only, which includes functions of internal services or imported functions from integrated libraries.
- Basic types of jobs (listed above) can be used to derive user defined job types. User defined job types serves as templates for reusing identical parts of job definitions, e.g. ssis job can be derived from system job and defined as a template for dtexec command line utility that is used to execute ssis package.
User defined job types
One of the powerful features of scheduler is extendible type system. Existing types of jobs (or other objects, e.g. lock) can be reused to create derived user defined types, which can predefine common attributes or override general attributes like command with an expression composing the value from more user friendly attributes. For example a user want to use a command line utility which has non-transparent options that are hardly to remember. Furthermore, many options remain unchanged for most of the jobs. In scheduler user can create new job type for this command line utility derived from system job. This new type will introduce new attributes one attribute for for each command line option that is expected to be used. Then the type will override attribute command with predefined path to the executable file of the utility and will also override attribute arguments with an expression that will compose command line arguments from the new options attributes. Jobs derived from this new type define only the necessary attributes and leave all the command line utility specialties on the derived job type.
Calendar, execution plan
Calendar defines list of holidays and time zone. Execution plan defines sequence of timestamps that are based on calendar and execution plan parameters. Execution plan can be defined as „execute daily at 2:00“, then the execution plan defines sequence of timestamps (time zone is not stated) …, 1.1.2010 2:00, 2.1.2010 2:00, 3.1.2010 2:00, … execution plan has parameters to constrain timestamp sequence for concrete or periodic amount of time unit (e.g. on second day of every third month at 1 hour am every second minute) time unit can be one of quarter, month, day/workday in month, day in week, last day/workday in month, hour, minute. Execution plan can be constrained by a start and/or an end date (e.g. plan is valid only until the end of the year) or by a daily window (e.g. execute only from 8:00 to 18:00). Job can be scheduled using more than one execution plan.
Web console
Scheduler user interface allows access in three different roles: superuser, administrator, operator and common user. Administrator is responsible for metadata administration, i.e. objects definitions. Runtime data is not allowed to be edited for administrator. On contrary, operator is responsible for runtime state of jobs, resources and runtime servers. That is why operator is allowed to modify (using predefined operation actions) runtime data and thus react on incidents. For example he is allowed to solve unpredicted job failures by restart or resolve, he can block temporarily set of jobs, target environments or stop runtime servers. But operator is not able to modify metadata, which are accessible to operator for reading only. Role user is for the other users of scheduler that are allowed only to see data but are not allowed to modify them however. Role superuser merges administrator and operator roles. These roles are also applied on database level i.e. for db api access.
Effective browsing, navigation, editing, operations
Console is designed and optimized for browsing and editing of dependency graphs containing big number of objects and dependencies. That is why we generally use tables for browsing data. In object details it is possible to find all direct dependencies and quickly navigate to them using hyperlinks. For another way to browse hierarchy we use tree. Objects in tables can be filtered and sorted.
Browsing and editing objects in console
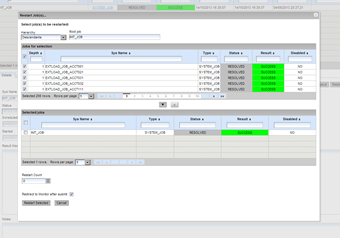
For bulk operations on jobs (e.g. restart, spool) there are specially design dialogs that helps to effectively select set of jobs with some properties. Upper table is used for browsing jobs in hierarchy towards predecessors of selected root job or towards its successors. Alternatively jobs can be listed without hierarchy. Jobs in the table can be filtered, sorted and then selected. Actual selection of jobs is shown in the lower table. When all required jobs are selected user can set up additional parameters of operation and confirm the operation. All modifications are processed in one database transaction.
Bulk operations on jobs
Monitoring
Overview of the current state of execution is shown and periodically updated in the left side panel. This gets a user general information about current state of processing. More detailed information about processing is available in monitoring view. This view contains several tables with important operational data about jobs (running, waiting, finished and waiting for resolve), event log and current state of the runtime server(s).
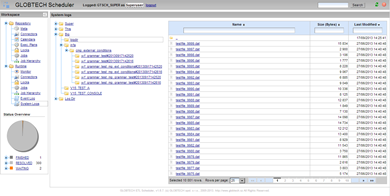
File system
Jobs and runtime server(s) generate lots of files e.g. system log file, standard output of system jobs or informatica log files. Console provides remote access to this files. User is able to browse them, sort, filter them or download them to local computer.
Remote file system explorer
User interface customization
UI interface can be customized on three levels:
- Environment styling – helps to differentiate different environments (e.g. development, test and production), this kind of styling changes color and title of the console header.
- Branding styling – is for changing style to assimilate ui with company gui standards.
- Detail customization – using css styling and templates with forms and tables layout.